Load testing a Drupal site with Locust
 What is Locust?
What is Locust?
Locust is an exciting new framework to do load testing on a site. Test scenarios are written in Python and are easily customizable. I used it to create benchmarks for a performance comparison of several cloud hosting providers.
There are several alternatives to Locust, such as the humble apache benchmark (ab), Siege, Proxysniffer and many others. Though, in my opinion, none of those offer the ability to realistically mimic site specific usage patterns, while still being incredibly easy to set up, providing a great interface for using it, and being open source.
It also offers features such as distributed load testing through a master/client setup as well as “ramping up” load testing to determine stability limitations, though I did not make use of those features.
Writing scripts
Since test scenarios are basically just python functions which are extending Locust’s base functions, one has to first outline the tasks a simulated user should make.
There is nothing wrong with simply specifying a list of urls (possibly parsing a sitemap.xml) and then relying on Locust to let requests randomly hit those URLs within predefined, randomized intervals. Based on the base example on Locust’s front page, the following works for a sitemap generated by Drupal’s XML Sitemap module:
#!/usr/bin/python
import random
from locust import Locust, TaskSet, task
from pyquery import PyQuery
class RandomSitemapWalk(TaskSet):
def on_start(self):
r = self.client.get("/sitemap.xml?page=1")
pq = PyQuery(r.content, parser='html')
self.sitemap_links = []
for loc in pq.find('loc'):
self.sitemap_links.append(PyQuery(loc).text())
@task(10)
def load_page(self):
url = random.choice(self.sitemap_links)
r = self.client.get(url)
class AwesomeUser(Locust):
task_set = RandomSitemapWalk
host = "http://www.example.com"
min_wait = 1 * 1000
max_wait = 10 * 1000
Now you can start Locust with that, set the number of users you want to be spawned and start testing your application. 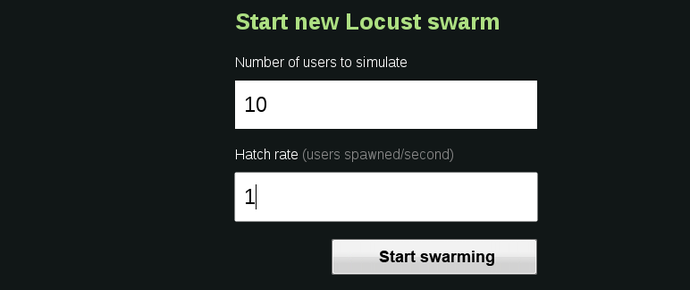
Those tasks by themselves aren’t that special, one could as easily parse the sitemap with awk/sed, pass it to Sieve and get a similar results. As the example on their front page shows, procedures such as logging in are trivial and there we can build complex workflows.
Profiling logged in users
Most of the time, anonymous requests aren’t really the optimization problem, at least if your node-to-hit ratio isn’t so low that Varnish isn’t already serving those users quickly. So, to simulate logged in users (as their primary example shows), all that’s needed is to POST to the login form, adapted to Drupal 6 this would be done as follows:
def on_start(self):
self.client.post("/user/login", {
"name": "loadtest@example.com",
"pass": "loadtest",
"form_id": "user_login",
"op": "Log in"
})
From there on we could either reuse our sitemap and let users randomly hit pages or do something with their second base tutorial “Example with HTML parsing” and start responding to the content actually delivered to a logged in user. The following would log in, read the front page, index all links, and choose a target at random. By itself that is rather limited compared to the sitemap set but it should be trivial to work out how to extend this to walk through a varying number of link depths:
class WalkPages(TaskSet):
def on_start(self):
self.client.post("/user/login", {
"name": "loadtest@example.com",
"pass": "loadtest",
"form_id": "user_login",
"op": "Log in"
})
# assume all users arrive at the index page
self.index_page()
@task(10)
def index_page(self):
r = self.client.get("/")
pq = PyQuery(r.content)
link_elements = pq("a")
self.urls_on_current_page = []
for l in link_elements:
if "href" in l.attrib:
self.urls_on_current_page.append(l.attrib["href"])
@task(30)
def load_page(self):
url = random.choice(self.urls_on_current_page)
r = self.client.get(url)
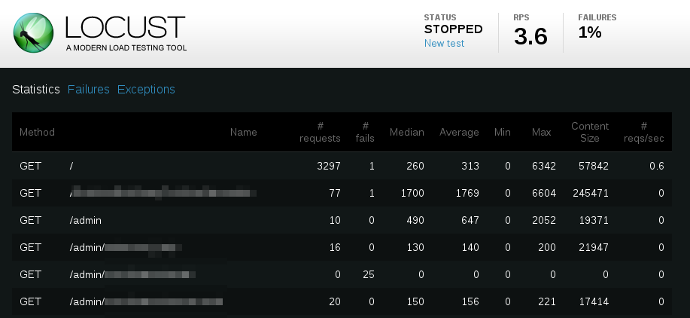
You can now download the results of these tests as CSV and analyze in depth on the basis of average page performance or fulfillment rate per percentage range per page, or simply store those results for future comparison.
Where to go from here
First of all, I think that defining use cases for a web project at the outset and defining a load testing script along those expected behaviours is a great step in modelling a platform before launch. Furthermore, it makes it easier to evaluate how additional features might impact a live site and its users before deployment. So, just writing a task list and then using Locust’s task priorities would be a great way to more closely emulate realistic user navigation paths.
What these examples don’t do is act on the Javascript on the pages retrieved. I was considering to attempt this with the pyv8 wrapper but haven’t gotten around to it yet.